增强对2D图像的3D理解的计算机视觉技术
在查看照片并借鉴他们过去的经历时,人类通常可以在本身完全平坦的图片中感知深度。然而,事实证明,让计算机做同样的事情非常具有挑战性。
由于几个原因,这个问题很困难,一个是当发生在三个维度中的场景被简化为二维(2D)表示时,信息不可避免地会丢失。有一些成熟的策略可以从多个2D图像中恢复3D信息,但它们都有一些局限性。由麻省理工学院和其他机构的研究人员开发的一种称为“虚拟通信”的新方法可以克服其中的一些缺点,并在传统方法学步履蹒跚的情况下取得成功。
标准方法,称为“运动结构”,以人类视觉的一个关键方面为模型。因为我们的眼睛彼此分开,所以它们各自提供的物体视图略有不同。可以形成一个三角形,其边由连接两只眼睛的线段以及将每只眼睛连接到所讨论对象上的公共点的线段组成。知道三角形中的角度和眼睛之间的距离,就可以使用初等几何确定到该点的距离——虽然人类的视觉系统当然可以对距离做出粗略的判断,而不必经过繁重的三角计算。几个世纪以来,天文学家一直在利用同样的基本概念——三角测量或视差视图来计算与遥远恒星的距离。
三角测量是运动结构的关键要素。假设你有两张物体的照片——例如兔子的雕刻人物——一张是从人物的左侧拍摄的,另一张是从右侧拍摄的。第一步是在兔子的表面上找到两个图像共享的点或像素。研究人员可以从那里确定两个摄像头的“姿势”——照片的拍摄位置和每个摄像头所面对的方向。知道相机之间的距离和它们的方向后,人们就可以通过三角测量来计算到兔子上选定点的距离。如果确定了足够多的共同点,就有可能获得物体(或“兔子”)整体形状的详细感觉。
这种技术已经取得了相当大的进步,博士Wei-ChiuMa评论道。麻省理工学院电气工程与计算机科学系(EECS)的一名学生,“现在人们匹配像素的精度越来越高。只要我们可以在不同的图像中观察到相同的点或多个点,我们就可以使用现有的算法来确定摄像机之间的相对位置。”但这种方法只有在两个图像有很大重叠时才有效。如果输入图像有非常不同的视点——因此包含的共同点很少(如果有的话)——他补充说,“系统可能会失败。”
在2020年夏天,马云想出了一种新颖的做事方式,可以极大地扩展运动结构的范围。当时麻省理工学院因而关闭,马云在的家中,在沙发上放松。看着自己的手掌,尤其是指尖,他突然想到,自己的指甲虽然看不到,却能清晰地描绘出来。
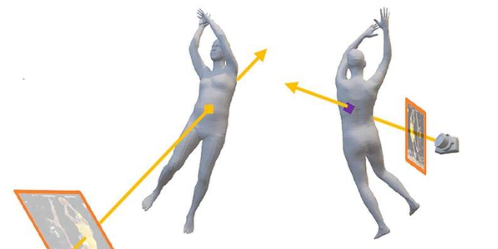
从2D图像重建3D场景的现有方法依赖于包含一些相同特征的图像。虚拟对应是一种3D重建方法,即使是从完全不同的视图拍摄的图像也不会显示相同的特征。图片来源:麻省理工学院
这就是虚拟通信概念的灵感来源,马云随后与他的导师AntonioTorralba(计算机科学与人工智能实验室的EECS教授和研究员)以及多伦多大学的AnqiJoyceYang和RaquelUrtasun一起追求和伊利诺伊大学的王申龙。“我们希望将人类知识和推理融入我们现有的3D算法中,”Ma说,同样的推理使他能够看到自己的指尖并在另一侧(他看不到的一侧)变出指甲。
当两个图像具有共同点时,运动结构就起作用了,因为这意味着始终可以绘制一个三角形,将相机连接到共同点,从而可以从中收集深度信息。虚拟通信提供了一种更进一步的方式。再次假设,一张照片是从兔子的左侧拍摄的,而另一张照片是从兔子的右侧拍摄的。第一张照片可能会显示兔子左腿上的一个点。但由于光线是直线传播的,因此人们可以利用对兔子解剖结构的一般知识来了解从相机到腿的光线会在兔子的另一侧出现在哪里。该点可能在另一幅图像中可见(从右侧拍摄),如果是这样,则可以通过三角测量使用它来计算第三维中的距离。
换句话说,虚拟对应允许人们从兔子左侧的第一个图像中获取一个点,并将其与兔子看不见的右侧的一个点连接起来。“这里的优势是你不需要重叠的图像来继续,”马指出。“通过观察物体并从另一端出来,这种技术提供了最初不可用的共同点。”并且通过这种方式,可以规避对传统方法施加的限制。
人们可能会询问需要多少先验知识才能使其起作用,因为如果您必须从一开始就知道图像中所有事物的形状,则不需要计算。马和他的同事们使用的技巧是使用图像中某些熟悉的物体(例如人形)作为一种“锚”,他们设计了利用我们对人形知识的方法来帮助确定相机姿势,在某些情况下,推断图像中的深度。此外,马解释说,“我们算法中内置的先验知识和常识首先由神经网络捕获和编码。”
马说,该团队的最终目标要雄心勃勃。“我们希望制造出能够像人类一样理解三维世界的计算机。”他承认,这个目标还远未实现。“但要超越我们今天所处的位置,建立一个像人类一样行动的系统,我们需要一个更具挑战性的环境。换句话说,我们需要开发不仅可以解释静止图像,还可以理解短视频剪辑和最终是完整的电影。”
电影“善意狩猎”中的一个场景展示了他的想法。观众从后面看到马特达蒙和罗宾威廉姆斯,他们坐在长凳上,俯瞰波士顿公共花园的池塘。下一张从对面拍摄的照片提供了背景完全不同的达蒙和威廉姆斯的正面(尽管穿着衣服)。每个看电影的人都会立即知道他们在看同一个人,尽管这两个镜头没有任何共同之处。计算机还不能实现这种概念上的飞跃,但马云和他的同事们正在努力让这些机器更熟练,并且至少在视觉方面更像我们。
该团队的工作将在下周的计算机视觉和模式识别会议上展示。
标签: