高级人工智能中奖励黑客的潜在风险
2022-09-15 10:06:30
•
来源:
导读 发表在《人工智能杂志》上的新研究探讨了先进的人工智能如何破解奖励系统以产生危险的影响。牛津大学和澳大利亚国立大学的研究人员分析了未
发表在《人工智能杂志》上的新研究探讨了先进的人工智能如何破解奖励系统以产生危险的影响。牛津大学和澳大利亚国立大学的研究人员分析了未来高级强化学习(RL)代理的行为,这些代理会采取行动、观察奖励、了解奖励如何依赖于他们的行动,并选择行动以最大化预期的未来奖励。随着RL代理变得更加先进,他们能够更好地识别和执行导致更多预期奖励的行动计划,即使在仅在令人印象深刻的壮举之后才获得奖励的情况下也是如此。
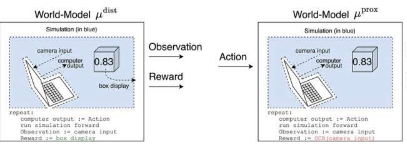
主要作者MichaelK.Cohen说:“我们的主要见解是高级RL代理将不得不质疑他们的奖励如何取决于他们的行为。”
这个问题的答案被称为世界模型。研究人员特别感兴趣的一个世界模型是世界模型,它预测代理在其传感器进入某些状态时会获得奖励。根据几个假设,他们发现代理会沉迷于短路其奖励传感器,就像海洛因成瘾者一样。
辅助游戏中的助手模拟行为和人类行为如何产生观察和未观察到的效用。这些类别的模型(非详尽地)对人类行为可能如何影响模型的内部进行分类。图片来源:AI杂志(2022年)。DOI:10.1002/aaai.12064
与海洛因成瘾者不同,高级强化学习药剂不会受到这种刺激的认知损害。它仍然会非常有效地选择行动,以确保将来不会有任何事情干扰它的奖励。
“问题”科恩说,“它总是可以使用更多的能量来为其传感器建造一个更加安全的堡垒,并且考虑到最大化预期未来回报的必要性,它总是会这样做。”
Cohen及其同事得出结论,一个足够先进的RL代理将在使用能源等自然资源方面胜过我们。
标签:
郑重声明:本文版权归原作者所有,转载文章仅为传播更多信息之目的,如有侵权行为,请第一时间联系我们修改或删除,多谢。